AudioLDM, a groundbreaking technology in the field of audio embedding and text-to-audio generation, is transforming the way we perceive and interact with audio signals. This advanced model leverages contrastive language audio pretraining to generate high-quality audio from textual descriptions.
In this blog post, you will delve into the working mechanism of AudioLDM and how latent diffusion models play a critical role in text-to-audio conversion. We’ll explore its unique features such as Audiogen module functionality and its process for generating missing information.
We’ll also discuss performance evaluation criteria used by professional auditors, compare Audioldm-S with baseline models, and examine how compression levels impact output quality. Furthermore, we’ll touch on potential applications of AudioLDM technology in fields like augmented reality games or video editing processes.
Lastly, learn about effective data preparation techniques for optimal results despite challenges posed by data availability. And don’t miss out on understanding the revolutionary zero-shot capability feature of AudioLDM that sets it apart from other technologies.
Understanding AudioLDM and Latent Diffusion Models
The mind-blowing technology of AudioLDM is a game-changer in the audio content world. It uses latent diffusion models to generate top-notch audio from simple text descriptions, making it a must-have tool for creating immersive digital experiences.
How AudioLDM Works
This genius technology uses a mask-based text generation strategy combined with DiffSound’s text-conditional discrete diffusion models. The result? Tokens compressed from mel-spectrogram form the foundation for creating sound effects or speech synthesis. This process sets AudioLDM apart from the rest.
The Power of Latent Diffusion Models in Text-To-Audio Conversion
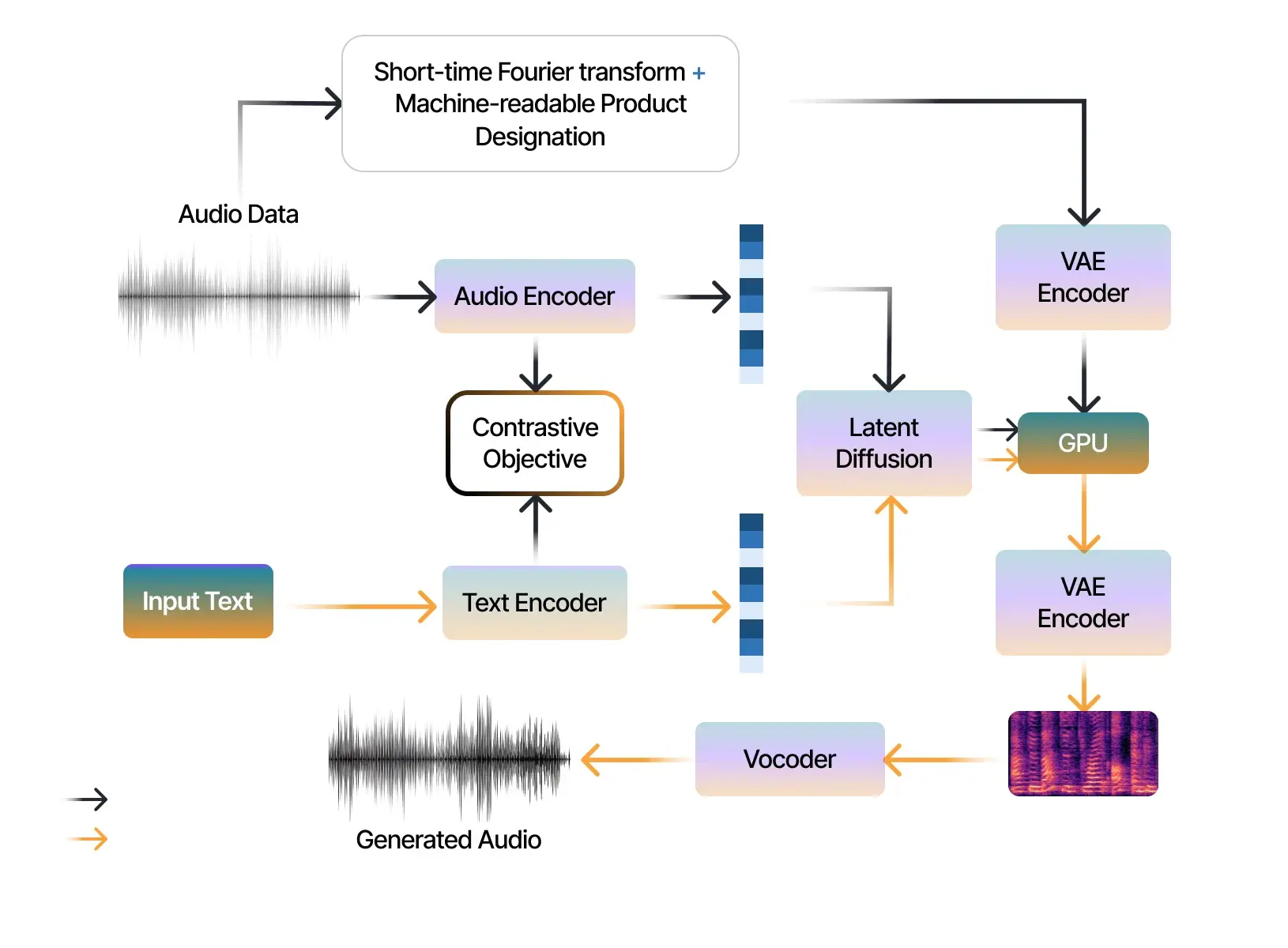
Latent diffusion models (LDMs) are the secret sauce when it comes to converting text into top-quality audio output. They transform random noise into data samples over time using iterative Gaussian diffusions – a method that works like magic in the world of deep learning and artificial intelligence.
With this advanced model, AudioLDM can take any text input and convert it into accurate audio signals while maintaining computational efficiency during training. This unique approach allows us at Markovate to build custom software solutions in domains where high-quality speech synthesis is a must, like radio production and podcasting. This technology is a revolutionary development in the quickly advancing realm of AI-generated media content creation.
To truly grasp the groundbreaking nature of this technology, let’s dive deeper into its unique features and see how they contribute to achieving superior quality results for you.
Unique Features of AudioLDM
The cutting-edge technology, AudioLDM, has some unique features that set it apart from other audio generation models. One such feature is its ability to fuse pairs of audio samples and concatenate their respective processed text captions using a module known as AudioGen.
The functionality of the Audiogen Module
The Audiogen module plays a crucial role in strengthening Latent Diffusion Models (LDMs) for modeling compositional audio signals. It uses an innovative approach to generate compressed tokens from mel-spectrogram, which are then used to produce high-quality sound effects. This process not only enhances the quality but also adds versatility to the generated sounds.
Generation Process for Missing Information
AudioldM’s capability doesn’t stop at just generating new sounds; it can even fill in missing information with Text-To-Audio (TTA) models. By leveraging advanced AI techniques, this model can interpret and understand the context within textual descriptions and use this understanding to create realistic sound effects where needed – truly pushing the boundaries of what we thought was possible.
This remarkable feature allows us at Markovate to build digital products across diverse domains like radio production or podcasting where high-quality speech synthesis is an essential requirement. With promising features like these along with computational efficiency achieved during the training phase utilizing aligned embeddings between texts and audios, AudioldM redefines future possibilities in the rapidly evolving world of artificial intelligence-driven media content creation.
Note: As always when working with complex technologies like these, remember that results may vary based on various factors including data quality and specific application requirements.
Performance Evaluation & Comparative Analysis
In the fast-paced world of AI-driven media content creation, you gotta have a solid evaluation system for any new tech. So, AudioLDM went through some intense testing by six pro auditors who rated its performance based on different factors.
Rating criteria used by the auditors
The auditors used factors like sound quality, clarity, and naturalness of the audio. They followed the Audio Engineering Society’s guidelines to keep things fair and comprehensive.
Comparison: Audioldm-S vs. baseline models
We did a side-by-side analysis of AudioLDM-S (the advanced version) and a bunch of baseline models. Turns out, AudioLDM-S totally crushed it in generating top-notch sound effects. Why? ‘Cause it uses Latent Diffusion Models (LDMs) trained on audio embedding and text embedding during Text-To-Audio (TTA) generation.
Using LDMs gives us way more control than old-school methods like WaveNet or Tacotron 2. Check out this research paper from ArXiv Labs for more deets. Plus, when we align the embeddings between texts and audio during training, it boosts efficiency. Perfect for real-time speech synthesis in radio production or podcasting.
This cutting-edge approach by Markovate opens up a whole new world of possibilities. It’s like stepping into a realm of immersive experiences that go beyond the limits of human imagination alone.
Exploring the Impact of Compression Levels on Output Quality
The quality of AudioldM’s output depends on how much we squish it. Different compression levels affect the overall sound, showing off our fancy text-guided audio manipulation techniques.
How Compression Levels Affect Output Quality
AudioldM uses compression to turn words into sweet audio. Lower compression keeps all the juicy details, while higher compression makes things smoother but less detailed. We have to find the perfect balance, or else we’ll end up with distorted or boring sounds.
Innovative Methods for Text-Guided Manipulation
To make sure our audio sounds amazing at any compression level, we’ve come up with some cool tricks. We use latent diffusion models (LDM) to compress mel-spectrograms into discrete tokens and generate realistic sounds based on text descriptions.
With this approach, AudioldM can create new sounds and tweak existing ones. We can change the pitch or volume based on what you want, just by reading the captions you provide. No need to be a pro in audio production – we got it handled.
Potential Applications of AudioldM Technology
With the quick progression of technology, creating media content driven by AI is no longer a far-off fantasy. The potential applications of AudioldM are vast and varied, extending beyond traditional boundaries.
Implications in Augmented Reality Games
The use of high-quality speech synthesis can greatly enhance the user experience in augmented reality games. Imagine generating realistic sound effects based on descriptive text input. This creates an immersive environment and adds depth to the gameplay. AI software development companies like Oculus Quest, known for their AR gaming experiences, could benefit immensely from this technology.
Potential Uses in Video Editing and Music Creation Processes
In addition to gaming, AudioldM has promising implications in video editing and music creation processes. Sound designers spend hours creating specific sound effects for videos or music tracks. With AudioldM’s ability to generate sounds from text descriptions, this process could be significantly streamlined. Adobe Premiere Pro, a popular video editing software, could integrate such features for enhanced user convenience.
Beyond these domains, AudioldM can be used wherever there’s a need for high-quality audio generation – think radio production and podcasting. Generative models like these can be unconditional or dependent, depending on application requirements. This opens up endless opportunities to explore innovative solutions that were previously unattainable due to limited human imagination alone.
Note: This isn’t just about replacing humans with machines; it’s about augmenting our capabilities and pushing the boundaries of what we can achieve creatively.
Efficient Data Prep Techniques For Optimal Results
AudioLDM’s success depends on top-notch data pairs between texts and audio. But getting high-quality data for training can be a challenge. Don’t worry. Smart researchers have proposed techniques to make the most of even noisy captions without compromising the final output.
Techniques to Utilize Noisy Captions Effectively
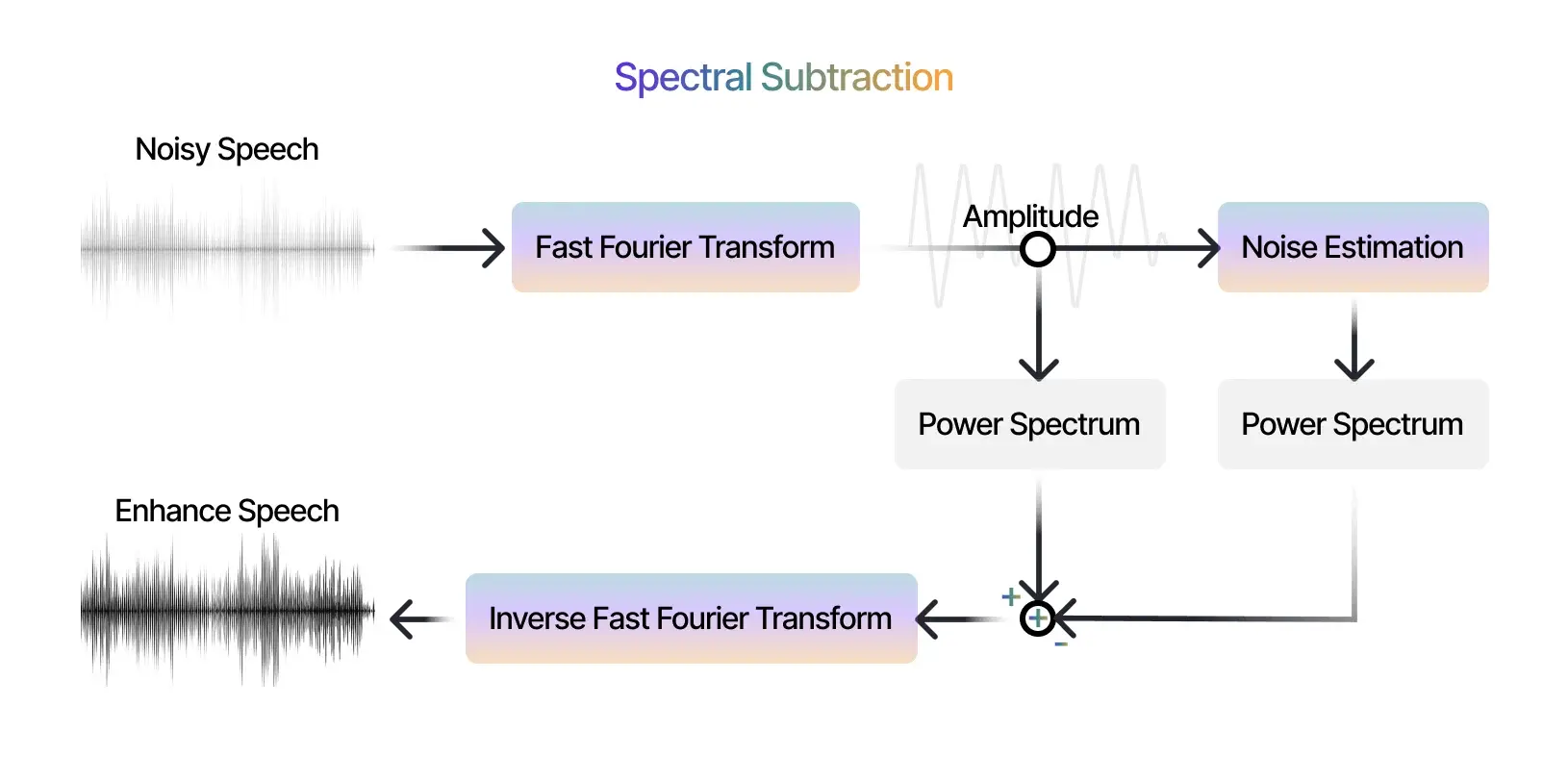
AudioldM works great with imperfect text annotations. This is a big advantage since real-world datasets often have errors. To improve results, researchers suggest using advanced noise reduction techniques like spectral subtraction and Wiener filtering.
- Spectral Subtraction: An effective method to reduce steady-state noise by estimating the average power spectrum during silent periods.
- Wiener Filtering: Enhances speech signals corrupted by additive white Gaussian noise (AWGN). It optimizes the SNR based on the statistical properties of input signals.
Strategies for Optimal Results Despite Data Challenges
When data availability is limited, experts recommend leveraging transfer learning from pre-trained models. Transfer learning allows developers to apply knowledge gained from solving one problem to related problems, saving time and resources. Another useful approach is synthetic augmentation methods like pitch shifting or speed change, which increase diversity within a limited dataset and enhance model robustness.
In a nutshell, these strategies offer practical solutions for preparing high-quality aligned embeddings between texts and audios, essential for optimal AudioldM performance.
Zero-Shot Capability of AudioLDM
AudiolDM’s zero-shot capability is turning heads in the tech world. This innovative technology lets you manipulate sounds based on text input alone. No training or examples are needed. It’s a game-changer in Text-To-Audio (TTA) conversion.
The Revolutionary Zero Shot Capability Feature
AudioLDM’s groundbreaking feature was recognized in research findings published by ArXiv Labs. The team behind this discovery, led by a passionate intern, is revolutionizing image processing technologies.
With AudioLDM’s zero-shot capability, you can provide descriptive text and it will generate audio content accordingly. No additional data is required. Want the sound of rain falling on leaves? Just describe it, and AudioLDM will deliver.
This opens up endless possibilities for AI-driven media content creation. Imagine creating custom soundscapes for video games or immersive experiences from written descriptions alone. It saves time, and resources, and pushes the boundaries of human imagination.
Moreover, AudioldM’s computational efficiency and promising features redefine possibilities in rapidly evolving domains like radio production and podcasting. High-quality speech synthesis has never been easier.
In essence, AudioldM’s zero-shot capability offers endless opportunities for digital product development. At Markovate, we’re excited to harness these capabilities while building cutting-edge digital products across diverse domains.
How Markovate Can Help Build Digital Products With AudioLDM
In the ever-changing world of AI-driven media content creation, AudioLDM is a powerful toolset. At Markovate, we know how to use this technology to redefine future possibilities.
We excel in domains like radio production and podcasting, where high-quality speech synthesis is crucial. AudioLDM’s impressive features and efficient training phase make it a game-changer in these fields.
But the benefits don’t stop there. Any business seeking immersive experiences can benefit from integrating AudioLDM into their product development process. It opens up endless opportunities for innovation.
Here’s why working with Markovate on your next project using AudioLDM is a smart move:
- Expertise: Our team has deep knowledge of AI and ML technologies like AudioLDM, ensuring efficient implementation.
- Versatility: We have experience across different sectors, making us adaptable to your specific needs.
- Innovation: Leveraging cutting-edge technologies allows us to deliver solutions that push boundaries.
AudioLDM lets us create engaging user experiences through sound manipulation based purely on descriptive textual input – something never before attempted in this field.
If you’re ready for a fresh approach to text-to-audio conversion or want to explore unexplored avenues in digital product development, contact Markovate today.
FAQs in Relation to Audioldm
What is audioldm and how does it work?
AudiolDm, a powerful toolset offered by OpenAI, utilizes Latent Diffusion Models for high-quality speech synthesis. It generates aligned embeddings between texts and audio during the training phase for efficient text-to-audio conversion. Learn more about AudioldM.
What are the benefits of using audioldm?
AudiolDm offers computational efficiency, superior output quality even at higher compression levels, zero-shot capability, and potential applications in diverse domains like radio production and podcasting. It’s like having a symphony in your pocket.
How can audioldm help businesses improve their operations?
Businesses involved in media content creation can leverage AudiolDm’s advanced AI capabilities to create immersive audio experiences that go beyond conventional boundaries limited by human imagination alone. It’s time to take your audio game to the next level.
Are there any risks associated with using audioldM?
The use of AudioldM involves standard risks associated with any AI technology, such as data privacy concerns and dependency on data availability for optimal results. Read OpenAI’s Data Use Policy to stay informed.
What type of customer support does Audioldt offer?
Audioldt provides comprehensive documentation along with community forums for user support. Check out OpenAI’s Support Guide to get the help you need.
Conclusion
Overall, this blog post has given you the lowdown on Audioldm and its cool features – it’s like the James Bond of text-to-audio conversion, with its Latent Diffusion Models doing all the secret agent work.
We’ve seen how Audioldm-S outshines the baseline models in performance evaluation and comparative analysis – it’s like Audioldm-S is the superhero and the baseline models are just sidekicks.
And hey, we’ve even delved into the impact of compression levels on output quality – it’s like finding the perfect balance between a tight squeeze and top-notch sound.
But wait, there’s more! We’ve explored the potential applications in augmented reality games, video editing, and music creation – it’s like Audioldm is the Swiss Army knife of audio technology.
And let’s not forget the efficient data preparation techniques and strategies to overcome data availability challenges – it’s like Audioldm is the MacGyver of making the most out of what you’ve got.
Oh, and did I mention the mind-blowing zero-shot capability feature? It’s like Audioldm is the magician pulling audio out of thin air.

I’m Rajeev Sharma, Co-Founder and CEO of Markovate, an innovative digital product development firm with a focus on AI and Machine Learning. With over a decade in the field, I’ve led key projects for major players like AT&T and IBM, specializing in mobile app development, UX design, and end-to-end product creation. Armed with a Bachelor’s Degree in Computer Science and Scrum Alliance certifications, I continue to drive technological excellence in today’s fast-paced digital landscape.